基于强化学习的室内热环境控制
清华大学建筑学院建筑技术科学 杨世纪 闫睿 福林
【摘 要】个性化的室内热环境控制可以提高使用者的热舒适度及建筑能源效率,本研究提出了一种基于生物传感和强化学习的室内热环境控制系统。该控制系统使用智能手环测定用户皮肤表面温度,采用强化学习方法Q-learning来确定用户的皮肤表面温度舒适范围,通过学习得到的Q-table预测用户当前热感觉并调整室内空调温度设定值。
【关键词】强化学习;个性化偏好;室内热环境控制
0 背景
舒适的室内热环境对于保持使用者的健康和生产力起着至关重要的作用,为建筑使用者提供舒适的热环境是建筑供暖和供冷系统运行的最重要目标之一。在目前的商业建筑中,往往采用统一的“一刀切”方式对建筑内热环境进行控制,即由建筑管理人员设置统一的室内温度设定值[1]。这种方法,一方面忽略了使用者对室内热环境的不同偏好,导致热满意率较低[2];另一方面也不利于充分发挥设定值优化带来的节能潜力,使得建筑的运营成本增加。如果根据使用者的个性化偏好进行室内热环境控制,不仅可以提高使用者的热舒适度,还可以在一定程度上降低建筑能耗[3]。因此,本文提出了一种基于强化学习的方法识别用户的个性化舒适域对室内热环境进行个性化控制的方法,并通过实验检验了用户对室内热环境控制效果的满意度。
1 控制系统介绍
1.1 Q-Learning算法
本研究提出的室内热环境控制系统主要基于改进后的Q-Learning算法,Q-Learning是强化学习的一种时间差分算法,而强化学习问题都可以建模为马尔可夫决策过程(MDP)进行求解[4]。
马尔可夫决策过程的理论基础为马尔可夫链和马尔可夫特性,马尔可夫链是一个概率模型,仅依赖于当前状态来预测下一个状态,而与之前的状态无关,马尔可夫特性表明未来只取决于当前而与过去无关,即马尔可夫链严格遵循马尔可夫特性。
马尔可夫决策过程是马尔可夫链的一种扩展,它提供了一个用于对决策情景建模的数学框架。马尔可夫决策过程可由五个关键要素表示:智能体当前所处的状态、从一种状态转移到另一种状态所执行的行为、转移概率、奖励概率及控制即时奖励和未来奖励的折扣因数。
本研究提出的基于Q-Learning算法的个性化室内热环境控制过程可近似看作一个马尔可夫决策过程,并利用Q函数(状态—行为值函数)对该过程进行模拟,Q函数适用于表明智能体遵循某一个策略在某一状态下执行特定行为的最佳程度,通过Q函数求得的Q值则反映了根据某个策略从当前状态采取特定行为所获得的期望回报。
Q函数主要包含三个关键要素:状态值(S),动作值(A),即时奖励(R),其表达式为:
Q(Si,A)=(1-α)Q(Si,Ai)+α[R+γQ(Si+1,Abest)] (1)
α表示学习速率,反映了经过一次迭代后对之前的训练效果的保留程度;
γ表示折扣因子,反映了相较于即时奖励,对未来奖励期望的重视程度;
Q(Si+1,Abest)表示智能体处于Si+1时的最大Q值,反映了未来奖励期望;
在本研究中,基于使用者个性化偏好的室内热环境控制系统的最终目标是长期维持一个让使用者感到舒适的室内热环境,因而它更看重使用者当前的热舒适状况而不是使用者未来热舒适状况的期望值,这一点体现在Q函数上就是折扣因子γ越小越好,在本研究中我们选择将折扣因子γ取零,即只看重使用者当前的热舒适状况,改进后的Q函数表达式为:
Q(Si,A)=(1-α)Q(Si,Ai)+αR (2)
1.2 状态获取
通过文献调研及相应的实验验证,我们认为人体皮肤表面温度能够在很大程度上反映人体热感觉,我们选择了一名受试者(夏季,服装热阻:0.5clo),将其置于一个空气温度由28.5℃逐步降至23.5℃的室内,每隔一分钟记录当前室内空气温度及受试者手腕处皮肤表面温度(通过智能手环获得)及其热感觉,数据采集共进行100次,实验结果如下所示:
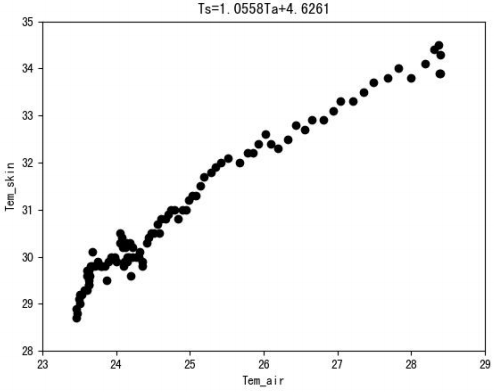
图1 受试者手腕处皮肤表面温度随环境温度的变化
图1的横坐标表示室内空气温度,纵坐标表示受试者手腕处皮肤表面温度,我们可以从图1中很明显地看出,在夏季,人体皮肤表面温度与室内空气温度具有非常明显的线性关系,这表明对于室内空气温度的变化,人体皮肤表面温度较为敏感,随室温基本呈线性关系。
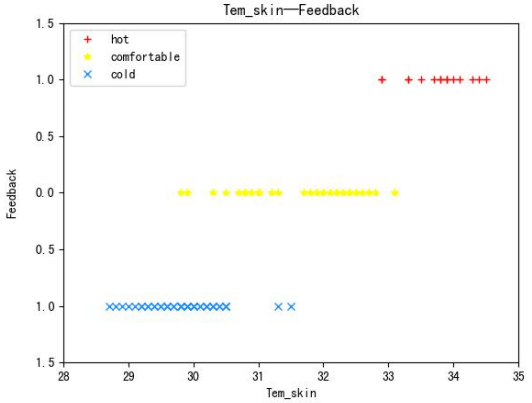
图2 受试者手腕处皮肤表面温度与热感觉的关系
图2的横坐标表示受试者手腕处皮肤表面温度,纵坐标表示受试者当前的热感觉,从图2可以看出,人体皮肤表面温度与人当前的热感觉具有非常明显的对应关系。
因此,本研究决定选择人体皮肤表面温度作为Q函数的状态值。本研究的后续实验发现,在夏季,人体皮肤表面温度一般处于27~36℃的范围内;即使室内空气温度恒定(在0.1℃范围内波动)且人热感觉基本没有变化,人体皮肤表面温度依旧在0.3℃范围内波动,即处于动态平衡状态。为尽可能避免上述因素的影响,本研究决定以0.5℃为步长将夏季人体正常皮肤表面温度范围(27~36℃)划分为18个状态值,其具体公式为:
S=(Ts-27.5)/0.5+1
其中S为状态值,Ts为人体皮肤表面温度;
1.3 动作与即时奖励
在Q-Learning的大多数应用场景(如倒立摆)中,由于智能体接收到的反馈只能评价上一个已经执行的动作而不能指导如何选择下一步动作值,智能体只能通过“依据‘ε-贪婪’策略选择特定行为,执行特定行为后获得即时奖励,通过即时奖励更新Q-table”的方式进行学习。而在本研究中,我们从受试者处接收到的冷热反馈,不仅可以对已执行的行为进行评价,而且在一定程度上还可以指导我们选择下一步行为,尤其是在训练的初始阶段。因此本研究在训练的初始阶段选择特定动作值的方式,并不是依据“ε-贪婪”策略,而是先通过受试者的冷热反馈对Q-table(用于记录智能体获得的经验)进行更新,而后依照Q-table及受试者当前所处状态值S来选择最优策略A,其具体流程如下所示:
1)初始化Q-table;
2)通过迭代训练完善Q-table:
3)测量室内空气温度Ta及皮肤表面温度Ts;
4)通过公式S=(Ts-27.5)/0.5+1计算得到当前状态值S;
5)从受试者处获得反馈并通过反馈更新Q-table;
6)根据当前状态值S及Q-table选择并执行最优策略A;
7)当受试者长时间感到舒适且Ts与Ta基本不变时,结束实验;
在本研究中,执行特定动作值的方式为改变室内空调设备的温度设定值;而即时奖励则是由受试者的反馈决定的,如当受试者给出一个热反馈时,控制系统会给予升温动作一个负奖励,降温动作一个正奖励。
2 实验验证
2.1 试验台介绍
该试验台房间面积为19.74 m2,长4.7m,宽4.2m,北侧墙体为外墙并设有外窗。房间内设有桌、椅等普通办公设施模拟群组办公情景,可容纳3人同时办公,且试验台设有空调设备与控制系统所需设备。
2.2 单人实验
我们选择了一名受试者(男青年),将其单独置于试验台房间内,调整室内空调设备初始设定值为26℃,每隔5min进行一次迭代训练,实验共进行2h(24次),实验结果如下图所示:
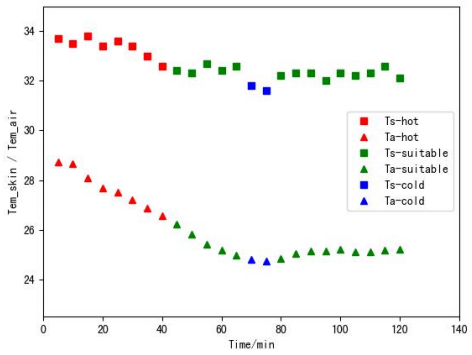
图3 单人实验时受试者皮肤温度及室温随时间的变化
从图3中,我们可以很明显地看出,在实验进行80min后,室内空气温度Ta基本维持在25.20.1℃范围内,受试者皮肤表面温度Ts维持在32.30.3℃范围内且受试者的热感觉始终为舒适。
2.3 多人实验
在验证了单人实验的可行性之后,我们接着开展了人数为3人(男青年,女青年,男中年)的多人实验。
将三名受试者置于试验台房间后,调整室内空调设备初始设定值为24℃,每隔10min进行一次迭代训练,实验共进行3h(18次),三名受试者皮肤表面温度随室内空气温度变化的关系如下图所示:
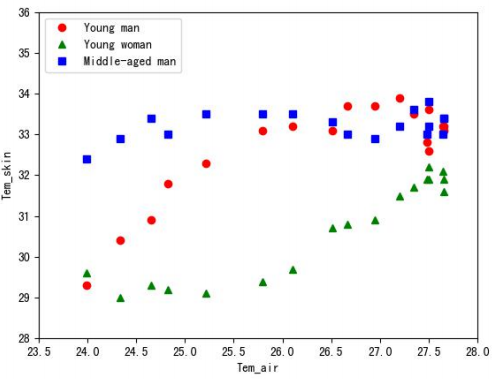
图4 三人实验时受试者皮肤温度随时间的变化
从图4可以看出,三名受试者由于性别、年龄的差异,其体表温度相对于室内空气温度的变化趋势不同,而多样化的受试者则能够更好地检验本研究所提出的个性化室内热环境控制系统在多人场景下的重要性。
由于三名受试者之间存在差异,对于相同的室内空气温度,不同的受试者可能会有不同的热感觉,为了更好地评价本研究所提出的控制系统在多人实验中的表现,决定每10min统计一次三名受试者对当前室内热环境的满意程度,其标准如下表所示:

我们将每10min三名受试者对当前室内热环境的满意度的平均值作为三名受试者对当前室内热环境的总满意度,其结果如下图所示:
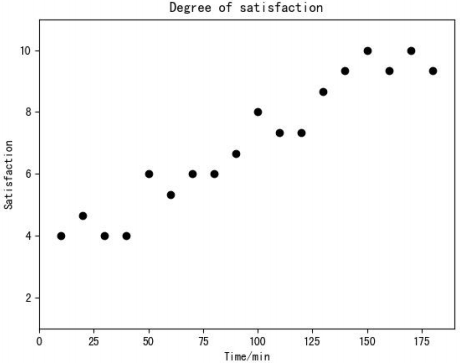
图5 三名受试者对室内热环境的满意度评价随时间的变化
从图5中,我们可以看出,三名受试者对室内热环境的总满意度随时间呈上升趋势,在实验后期,甚至出现了三名受试者对室内热环境均非常满意的情形。
3 研究结论
本文提出了一种基于强化学习Q-learning方法识别用户的个性化舒适域,对室内热环境进行个性化控制的方法,进行了实验,检验了用户对室内热环境控制效果的满意度。实验表明,本研究提出的室内热环境控制系统无论是在单人还是多人情景下均具有较好的热环境控制效果,受试者的满意度随着学习过程的进行逐渐提高。达到受试者非常满意的状态下的夏季空调温度的设定值高于多数建筑实际设置的室温设定值,具有一定降低建筑能耗的潜力。
4 致谢
国家自然科学基金资助课题,课题编号51578305和61425027。
参考文献:
[1] 王福林,韩典杉,孙泽禹,文世真,龚子阳,郁文红.室内热环境自动控制方法综述[J].暖通空调,2017,47(12):1-7.
[2] 王福林,冯晴晴,毛焯,陈哲良,赵千川,程志金,郭枝,张宇峰,麦锦博.室内热环境控制中房间用户冷热抱怨行为特征的实验研究[J].暖通空调,2017,47(09):40-44+48.
[3] 王福林,陈哲良,江亿,赵千川,程志金,郭枝,钟志鹏.基于热感觉的室内热环境控制[J].暖通空调,2015,45(10):72-75.
[4] 刘建伟,高峰,罗雄麟.基于值函数和策略梯度的深度强化学习综述[J/OL].计算机学报, 2018:1-38[2019-06-10].
备注:本文收录于《建筑环境与能源》2021年4月刊 总第42期(第二十届全国暖通空调模拟学术年会论文集)。版权归论文作者所有,任何形式转载请联系作者。