基于数据驱动的商业办公建筑冷量预测模型研究
清华大学建筑节能研究中心 康旭源 燕达 孙红三
太古地产有限公司 邱万鸿
【摘要】商业建筑能耗在总建筑能耗中占有重要的比例,根据商业建筑的特征有针对性地进行能耗预测和优化控制具有重要的意义。随着传感器技术的不断发展,建筑自动化系统不断丰富和完善,采集了大量真实的商业建筑能耗数据。因此,有必要基于商业建筑真实的冷量数据进行建筑冷量的特征分析和预测计算。本文采用了数据驱动模型进行商业办公建筑的冷量预测,基于商业建筑工作日与休息日典型用能行为的差异,首先对冷量的典型模式特征及其时间分布进行聚类分析,并在此基础上对比五种人工智能机器学习算法在冷量预测方面的效果,通过参数调优和交叉验证提高模型的预测效果。本文以香港某商业建筑为例进行了案例分析,并对比了分析结果。从结果中可以看出,数据驱动模型可以有效和高效地对商业建筑的冷量进行预测分析,并对建筑能源系统的优化控制提供技术支撑。
【关键词】建筑能耗、数据驱动、商业建筑、冷量预测、机器学习
【基金项目】本研究受清华大学-太古地产联合研究中心资助
1 研究背景
近年来,我国建筑能耗呈现不断增长的趋势。截至2018年,我国建筑运行过程的总商品能耗已经达到了10亿tce,占全国能源消费总量的22%。其中公共建筑运行能耗达到了3.32亿tce,占建筑总商品能耗的33%[1]。公共建筑面积仅占建筑面积总量的1/5,然而其能耗却占建筑总运行能耗的近1/3,因此,科学研究和分析公共建筑的能耗,对指导公共建筑节能具有重要的意义。
商业建筑的节能很大程度上依赖于对建筑运行阶段的能耗分析和预测,并基于预测值对建筑能源系统进行优化控制。在商业建筑运行调控阶段,由于建筑的物性参数以及人行为相关的因素的不确定性,因此,传统的建筑能耗模拟方法及模拟软件不能很好地适应于实际的能耗特征分析及预测的需求[2]。随着人工智能技术和机器学习算法的快速发展,数据驱动模型得到了长足的发展和广泛的应用[3]。数据驱动模型基于大量的历史数据,提取实际建筑运行过程中的能耗特征,并基于历史特征对未来的建筑能耗进行分析和预测。由于数据驱动模型是基于建筑真实的历史数据进行分析和预测,因此在商业建筑运行阶段的能耗分析中具有广泛应用和发展。
许多学者都针对机器学习算法在商业建筑能耗的分析展开了研究。周芮锦等人[4]基于逐月积温值、逐月平均相对湿度、逐月工作日天数和逐月非工作日天数四个因素,利用时间序列分析的方法ARMA构建数据驱动模型,实现对商业建筑的逐月能耗预测。Kwok, S等人[5]应用PENN(Probabilistic Entropy-based Neutral Network)算法构建了办公建筑的冷量预测模型,通过室外气象参数、有人房间面积和新风机功率对冷负荷进行预测,以香港某写字楼为例进行了冷量预测分析。肖赋等人[6]提出了基于数据挖掘技术的商业建筑系统性能分析和能耗预测模型,综合了时序分析、递归特种消除和整体学习等算法实现了下一日建筑总能耗和能耗峰值的预测。Fan, Cheng等人[7]基于深度学习(Deep learning)的算法强化了对建筑能耗的实时预测,在简单神经网络模型的基础上引入了时序特性,实现了商业建筑能耗的预测分析。除此以外,还有诸多研究[8][9]针对商业建筑冷量预测的数据驱动模型开展算法和案例分析。
本文基于数据驱动模型对商业建筑的冷量预测进行了分析研究。基于建筑BAS系统的实际冷量数据,对商业建筑的典型冷负荷特征进行聚类分析,并在聚类分析的基础上,引入多种机器学习算法,对建筑实时冷量进行预测分析和模型优化,并横向对比不同算法在预测精度和计算时长上的预测效果。最后文章总结和展望了基于数据驱动的冷量预测模型在实际商业建筑系统能耗分析中的特点以及应用前景。
2 研究方法
本文基于数据驱动的方法构建商业建筑冷量预测模型。由于商业建筑中随工作日、休息日的人行为变化具有不同的典型能耗特征,因此首先采用基于k-means的聚类分析方法分析典型冷量模式。在此基础上,综合采用和对比ANN、SVM、XGB、RF和LSTM五种冷量预测算法,对建筑冷量进行预测分析,并以实际冷量数据对模型的预测效果进行评估,以预测评估的结果对冷量预测模型进行参数调优和反馈优化,得到预测效果最优的模型。该冷量预测模型可以在建筑供冷的实时控制和蓄冷系统的预测控制等方面应用,为建筑能源系统的优化控制提供技术支撑。本研究的技术路线图如下:
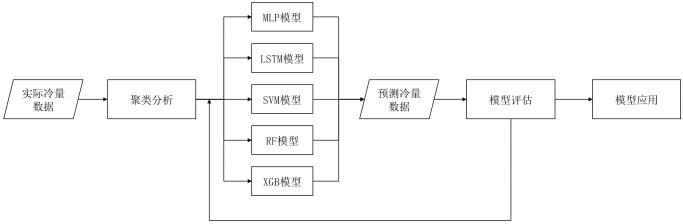
图1 研究技术路线图
由于实际建筑中的冷量需求很大程度上受到人用能行为的影响,因此,对实际建筑的典型用能模式分析非常重要。本文采用k-means的方法对建筑日冷量曲线进行聚类分析,以获取典型的用冷模式。K-means方法是一个经典的基于距离的聚类算法,可以将样本划分为特定数目的类,使类内相似度最大,类间区分度最高。
由于该算法需要预先确定聚类数,因此本文采用3个评价指标对聚类数进行选择和确定。第一个指标是轮廓系数(Silhouette Coefficient),结合内聚度和分离度两种因素,评价聚类的效果,该指标越大则聚类效果越好。第二个指标是CH指标(Calinski-Harabaz Index),该指标反映类间距离与类内距离的比值,其值越大则聚类效果越好。第三个指标是DB指标(Davis-Bouldin Index),该指标反映了类内平均距离与两聚类中心平均聚类的比值,其值越小聚类效果越好。通过在一定范围内遍历聚类数目,并综合三种评价指标,选择聚类效果最优的聚类数。
基于典型负荷模式,分别采用五种机器学习算法,拟合建筑冷量与各影响因素的关系。所采用的算法包括多层感知器神经网络(Multiple Layer Perception, MLP)、长短记忆法人工神经网络(Long Short Term Memory, LSTM)、支持向量机(Support Vector Machine, SVM)、随机森林(Random Forest, RF)、梯度提升决策树(Extreme Gradient Boosting, XGB)。
多层感知器是一种前馈人工神经网络,将多维数据集映射到单一输出的形式。通过多层神经元的全连接和非线性激活函数实现自变量至因变量的相关关系构建。长短记忆法的神经网络是一种改进之后的循环神经网络,通过门式神经网络控制长期状态和短期状态的记忆,以记录周期性特征。支持向量机是通过核方法将原始特征空间映射到更高维的空间,并在高维空间中实现线性拟合。随机森林是一种基于决策树的分类拟合器,通过构建系列决策树进行拟合。梯度提升决策树是基于决策树的优化形式,通过优化树的选择和分裂过程优化预测结果。
通过以上介绍的五种算法,分别进行建筑冷量预测模型的训练,并对下一日的逐时冷量进行预测分析。
3 案例分析
本节以香港某商业建筑的冷量预测分析为例,对比分析数据驱动模型。该案例为商业办公建筑,能耗数据来源于建筑BAS系统的冷量监测数据,时间跨度为2019年6月1日至10月30日,共152天的数据,数据时间间隔为15分钟。除此以外,还获取了香港国际机场气象站的逐半小时气象参数,包括室外干球温度、风速和云量。依此数据,对该案例的冷量进行建模分析和预测。
将该建筑的冷量数据以天为单位进行划分,得到152天的日冷量曲线。通过K-means算法进行聚类,并用三项指标评价最优聚类数。各聚类指标的结果如图 2所示。

图2 确定最优聚类数的三项聚类指标图
通过以上三个图线可以看出,聚类数k=3时轮廓系数最大,以轮廓系数为指标时k=3聚类效果最好;聚类数k=4时CH指数最大,以CH指数为指标时k=4聚类效果最好;聚类数k=3时,DB指数最小,以DB指数为指标时k=3聚类效果最好。综合以上三项指标,可以看出最优聚类数为3,即存在三类典型负荷模式。
将所有日冷量曲线按聚类数为3进行k-means聚类,并统计其在周中的分布,得到的结果如下图所示。第0类(Cluster 0)为周六模式,其存在明显的晨间负荷尖峰,并在早8时-15时处于负荷高峰状态,15时后负荷降低,进入负荷低谷时段;第1类(Cluster 1)为周日和节假日模式,该模式全天负荷均处于平峰状态,没有明显的负荷高峰;第2类(Cluster 2)为工作日模式,主要分布于周一至周五,该模式存在明显的晨间负荷尖峰,并在早8时至晚8时呈现负荷高峰状态。
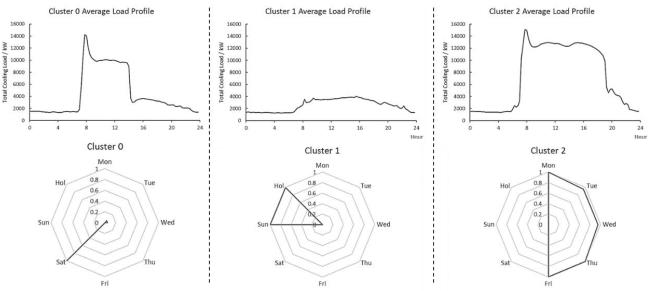
图3 典型日冷量负荷模式及其分布
以上三种模式在周内的分布十分明显,区分度十分高。并且三种模式特点显著且迥异,说明工作日/休息日类型是影响该案例负荷曲线和负荷特征的关键因素,后续分析中将以此作为重要的特征因素。
在以上聚类分析的基础上,综合采用上述5种算法,对建筑能耗进行预测分析。为了客观评估的预测效果,将原始数据集以天为单位随机划分为训练集、验证集和测试集,选取60%的样本为训练集,用以训练模型;30%的样本为验证集,用以优化模型和参数调优;10%的样本为测试集,作为最后评估模型预测效果的数据集。分别对以上五种模型进行模型训练、参数调优和对比评估,并分别抽取6、7、8月的某几日数据展示结果如下。
图 4展示了多层感知器(MLP)模型的预测结果。从图线中可以看出,模型大体上可以反映案例建筑的负荷趋势特征,但在一些特定时刻预测精度有较大偏差。该模型综合训练误差RMSE为1001.6,验证误差RMSE为1252.7,测试误差RMSE为1398.4。然而该模型计算时间较长,训练时长长达6.5小时,预测时长也需要10分钟,计算成本较高。(注:此处计算时长的数据统计于配置为, CPU i7-7700HQ @2.80 GHz, RAM 8.00GB计算机的计算时长。模型训练时长包括训练和参数调优过程的总时长,后同。)
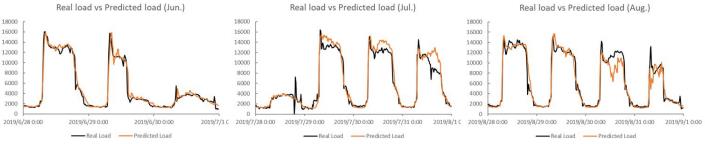
图4 MLP模型预测结果
图 5展示了长短记忆法人工神经网络(LSTM)模型的预测结果。从图线中可以看出,模型大体上可以反映案例建筑的负荷水平,但细节上有较大的预测偏差。该模型综合误差指标水平与MLP模型接近,训练误差RMSE为1017.1,验证误差RMSE为1335.8,测试误差RMSE为1430.1。然而该模型计算时间相对适中,训练时长为32分钟左右,预测时长为1分钟左右,计算成本适中。
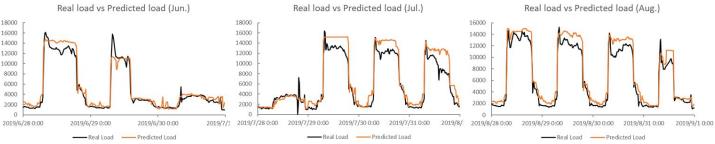
图5 LSTM模型预测结果
图 6展示了支持向量机(SVM)模型的预测结果。从图线中可以看出,该模型与实际数据有明显偏差,不能很好地反映冷负荷的趋势性特征。该模型综合训练误差RMSE为2416.4,验证误差RMSE为2389.5,测试误差RMSE为2094.7。该模型计算时间相对较短,训练时长为11分钟左右,预测时长为3秒钟左右,计算成本较低。
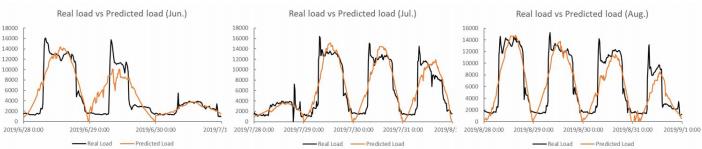
图6 SVM模型预测结果
图 7展示了随机森林(RF)模型的预测结果。从图线中可以看出,该模型与实际数据拟合程度较好,只在一些细节上有明显的偏差。该模型综合训练误差RMSE为554.9,验证误差RMSE为727.1,测试误差RMSE为1053.7。该模型计算时间相对较短,训练时长为6分钟左右,预测时长为2秒钟左右,计算成本较低。

图7 RF模型预测结果
图 8展示了梯度提升决策树(XGB)模型的预测结果。从图线中可以看出,该模型与实际数据拟合程度较好,只在一些细节上有细微的偏差。该模型综合训练误差RMSE为576.7,验证误差RMSE为704.1,测试误差RMSE为906.8。该模型计算时间相对较短,训练时长46分钟左右,预测时长为0.2秒左右,计算成本非常低。

图8 XGB模型预测结果
综合以上5种算法,分别对比了其预测精度和计算时长的差异,如图 9和表 1所示。

图9 五种模型预测误差对比
表1 五种模型计算时长对比
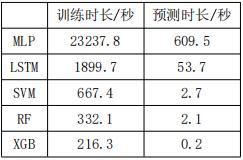
通过可以看出,以预测误差RMSE为标准,XGB模型的预测误差最小,预测精度最高。从模型的训练和预测时长比较,XGB模型耗时最短,计算效率最高。综合以上两个因素初步分析,XGB模型无论在预测精度还是在计算时长上都显著优于其他4种模型,在实际商业建筑的冷量预测中具有更好的预测效果。
4 总结
商业建筑中的冷量特征分析与逐时冷量预测对建筑供冷系统的优化控制具有重要意义。传统建筑能耗模拟过程与建筑的实际运行状态存在差异,而数据驱动模型基于真实的建筑能耗数据,可以客观反映和预测商业建筑的能耗。本文基于数据驱动模型,以商业建筑的冷量预测为例,探索了建筑能耗和负荷数据的预测分析方法,并以香港某商业建筑的实际能耗数据为例进行了预测分析,挖掘了实际商业建筑的集中典型用能模式,并在此基础上训练、优化和对比了5种机器学习算法在预测精度和计算时长上的差异。
通过结果初步分析可以发现,XGB、RF等模型具有较好的预测精度和效果。以上仅从数据分析的角度评估了不同算法的预测精度和计算时长,在实际应用过程中仍需依据物理机理和传热过程综合比较和选择如长短记忆法等不同算法内核,并构建适应于实际商业建筑案例的冷量预测模型。该案例体现了机器学习模型在建筑负荷分析的过程中,利用真实的冷量监测数据可以很好地捕捉商业建筑冷量的特征,应用于商业建筑供冷系统的运行调节和控制。
参考文献
[1] 清华大学建筑节能研究中心. 中国建筑节能年度发展研究报告2020[M]. 北京: 中国建筑工业出版社, 2020.
[2] 燕达,陈友明,潘毅群,et al.我国建筑能耗模拟的研究现状与发展[J].建筑科学,2018,34(10):130-138.
[3] Amasyali, K., & El-Gohary, N. M. (2018). A review of data-driven building energy consumption prediction studies. Renewable and Sustainable Energy Reviews, 81, 1192-1205.
[4] 周芮锦,潘毅群,黄治钟.基于时间序列分析的建筑能耗预测方法[J].暖通空调,2013,43(08):71-77.
[5] Kwok, S. S., & Lee, E. W. (2011). A study of the importance of occupancy to building cooling load in prediction by intelligent approach. Energy Conversion and Management, 52(7), 2555-2564.
[6] 肖赋,范成,王盛卫.基于数据挖掘技术的建筑系统性能诊断和优化[J].化工学报,2014,65(z2):181-187.
[7] Fan, Cheng,Xiao, Fu,Zhao, Yang. A short-term building cooling load prediction method using deep learning algorithms[J].Applied energy,2017,195:222-233.
[8] 范成,叶曈曈,王家远, et al.基于可解读机器学习的建筑冷负荷预测模型评估方法[J].建筑节能,2019,47(10):26-32,49.
[9] Tian, Zhe,Zhu, Neng,Guo, Qiang, et al. An improved office building cooling load prediction model based on multivariable linear regression[J].Energy and buildings,2015,107(Nov.):445-455.
备注:本文收录于《建筑环境与能源》2020年10月刊 总第37期(第22届全国暖通空调制冷学术年会文集)。版权归论文作者所有,任何形式转载请联系作者。